Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Does Bing ignore robots txt files?
-
Bonjour from "Its a miracle is not raining" Wetherby Uk
")
Ok here goes... Why despite a robots text file excluding indexing to site
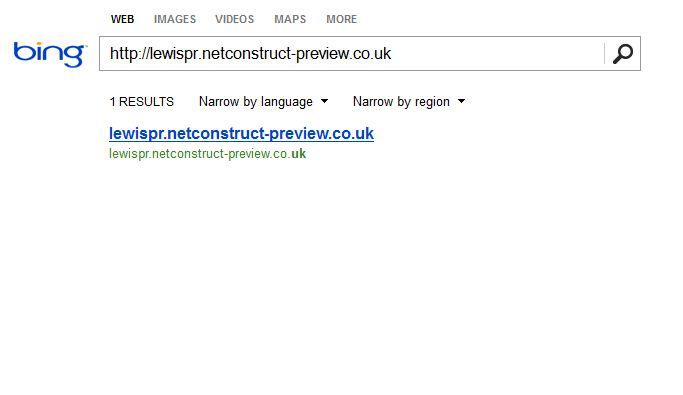
http://lewispr.netconstruct-preview.co.uk/ is the site url being indexed in Bing bit not Google?
Does bing ignore robots text files or is there something missing from http://lewispr.netconstruct-preview.co.uk/robots.txt I need to add to stop bing indexing a preview site as illustrated below.
http://i216.photobucket.com/albums/cc53/zymurgy_bucket/preview-bing-indexed.jpg
Any insights welcome
-
Thanks Clever PHD - we are now adding your recommendations to our preview sites
-
I know this does not sound related, but Matt Cutts explains this same situation on Google. It is probably the same reasoning for Bing.
http://www.mattcutts.com/blog/robots-txt-remove-url/
Looking at your screen shot, it looks as if all that is being shown in Bing is just the URL, no title tag, description, no other information.
What Matt says is that they did not technically crawl the url, but they are aware that it exists. Example, there is another page linking to it with related content or the anchor tag on the link relates to the keyword search you are performing.
You are searching for the URL specifically and so it makes sense that they would show the URL as it relates to that search, but they are not showing any information from the page as they do not have it as they did not spider it, again, they are just aware of the URL. Kind of like talking to a lawyer eh?
If you search for any other keywords does this excluded site show up? Probably not. If the do, then they are probably only showing the URL like in the example above.
The video has more details. Here are the solutions he gives, I will outline them as well
-
Use the Bing URL removal tool - bing bang boom. Done.
-
(my new favorite) Let the page / site be indexed but then show an noindex nofollow meta tag on the page / site. There is a subtle but important difference in the meta tag vs the robot.txt file. The spiders have to be able to crawl the page to be able to see what they are supposed to do with it.
http://support.google.com/webmasters/bin/answer.py?hl=en&answer=93710
"When we see the noindex meta tag on a page, Google will completely drop the page from our search results, even if other pages link to it."
The thing is, if you have a robots.txt file that says don't crawl the site, then the spider never gets to the noindex meta tag to know to delete the page from the index. It sounds a little backwards, but when the page is already in the search index, you have to let the spider crawl it to then see the noindex tag so that the search engine will know to remove it from the index.
Here is what you can do as this seems to only be an issue with Bing and just with the home page. Open up the robots.txt to allow Bing to crawl the site. Restrict the crawling to the home page only and exclude all the other pages from the crawl.
On the home page that you allow Bing to crawl, add the noindex no follow meta tag and you should be set.
All of that said.
If you have a single URL listed in bing with no meta data, it may not be worth all the above effort as you are not ranking for any valuable key words, but that is your call It is always interesting to see how the spiders and engines think so I wanted to pass this along.
Cheers!
PS - If you have a ton of pages like this - then you just would allow Bing to crawl them all and add the noindex nofollow tag to all of them.
-
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Why does Bing bot crawl so aggressively?
We observer that the Bing bot is crawling our site very aggressively. We set Bing's crawl control so that it should not crawl us during heavy traffic hours, but that did not change a thing. Does anyone have the problem and even better a solution?
Technical SEO | | Roverandom1 -

Robots.txt on subdomains
Hi guys! I keep reading conflicting information on this and it's left me a little unsure. Am I right in thinking that a website with a subdomain of shop.sitetitle.com will share the same robots.txt file as the root domain?
Technical SEO | | Whittie0 -

Blocking Affiliate Links via robots.txt
Hi, I work with a client who has a large affiliate network pointing to their domain which is a large part of their inbound marketing strategy. All of these links point to a subdomain of affiliates.example.com, which then redirects the links through a 301 redirect to the relevant target page for the link. These links have been showing up in Webmaster Tools as top linking domains and also in the latest downloaded links reports. To follow guidelines and ensure that these links aren't counted by Google for either positive or negative impact on the site, we have added a block on the robots.txt of the affiliates.example.com subdomain, blocking search engines from crawling the full subddomain. The robots.txt file is the following code: User-agent: * Disallow: / We have authenticated the subdomain with Google Webmaster Tools and made certain that Google can reach and read the robots.txt file. We know they are being blocked from reading the affiliates subdomain. However, we added this affiliates subdomain block a few weeks ago to the robots.txt, but links are still showing up in the latest downloads report as first being discovered after we added the block. It's been a few weeks already, and we want to make sure that the block was implemented properly and that these links aren't being used to negatively impact the site. Any suggestions or clarification would be helpful - if the subdomain is being blocked for the search engines, why are the search engines following the links and reporting them in the www.example.com subdomain GWMT account as latest links. And if the block is implemented properly, will the total number of links pointing to our site as reported in the links to your site section be reduced, or does this not have an impact on that figure?From a development standpoint, it's a much easier fix for us to adjust the robots.txt file than to change the affiliate linking connection from a 301 to a 302, which is why we decided to go with this option.Any help you can offer will be greatly appreciated.Thanks,Mark
Technical SEO | | Mark_Ginsberg0 -

Two META Robots tags on a page - which will win?
Hi, Does anybody know which meta-robots tag will "win" if there is more than one on a page? The situation:
Technical SEO | | jmueller
our CMS is not very flexible and so we have segments of META-Tags on the page that originate from templates.
Now any author can add any meta-tag from within his article-editor.
The logic delivering the pages does not care if there might be more than one meta-robots tag present (one from template, one from within the article). Now we could end up with something like this: Which one will be regarded by google & co?
First?
Last?
None? Thanks a lot,
Jan0 -

Site not ranking in Google but comes up #1 in Yahoo and Bing
Hi everyone, I've been working on SEO for this site for about 2 years and for some reason the site has just tanked in google. However it shows up #1 in yahoo and bing for the same search. http://www.nfsmn.com Phrase: "commercial foundation repair mn" If anyone can shed some light on the issue I would really appreciate it. They do have a sister-site: american-waterworks.com that may be causing issues as they link a lot of content to amww but not the other way around. Thanks Eric
Technical SEO | | reynoldsdesign0 -

301 Redirect on a PDF, DOCX files?
Hi, I have to rename many pdf and docx files. How can I implement 301 redirect on them as they are linked from 'n' number of places? Regards, Shailendra Sial
Technical SEO | | IM_Learner1 -

Should I set up a disallow in the robots.txt for catalog search results?
When the crawl diagnostics came back for my site its showing around 3,000 pages of duplicate content. Almost all of them are of the catalog search results page. I also did a site search on Google and they have most of the results pages in their index too. I think I should just disallow the bots in the /catalogsearch/ sub folder, but I'm not sure if this will have any negative effect?
Technical SEO | | JordanJudson0