Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Blocking certain countries via IP address location
-
We are a US based company that ships only to US and Canada. We've had two issues arise recently from foreign countries (Russia namely) that caused us to block access to our site from anyone attempting to interact with our store from outside of the US and Canada.
1. The first issue we encountered were fraudulent orders originating from Russia (using stolen card data) and then shipping to a US based International shipping aggregator.
2. The second issue was a consistent flow of Russian based "new customer" entries.
My question to the MOZ community is this: are their any unintended consequences, from an SEO perspective, to blocking the viewing of our store from certain countries.
-
Both answers above are correct and great ones.
From a strategical point of view, formally blocking russian IPs does not have any SEO effect in your case, because - as a business - you don't even need an SEO strategy for the Russian market.
-
Fully agree with Peter, very easy to bypass IP blocking these days, there are some sophisticated systems that can still detect but mostly outside the range of us mere mortals!
If you block a particular country from crawling your website it is pretty certain you will not rank in that country (which I guess isn't a problem anyway) but I suspect this would only have a very limited (if any) impact on your rankings in other countries.
We have had a similar issue, here are a couple of ideas.
1. When someone places an order use a secondary method of validation.
2. With the new customer entries/registrations make sure you have a good captcha, most of this sort of thing tends to be from bots. A captcha Will often fix that problem.
-
Blocking IPs on geolocation can be dangerous. But you can use MaxMind GeoIP database:
https://github.com/maxmind/geoip-api-php
or you also can implemente GeoIP in "add to cart" or "new user" as additional check. So when user is outside of US/CA you can require them to fill captcha or just ignore their requests.Now from bot point of view - if bot visit with US IP and with UK (example) IP they will see same pages. Just within UK they can't create new user or adding to cart. HTML code will be 100% same.
PS: I forgot... VPN or Proxies are cheap these days. I have few EC2 instances with everything just for mine own needs. Bad Guys also can use them so think twice about possible "protection". Note the quotes.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

How do I "undo" or remove a Google Search Console change of address?
I have a client that set a change of address in Google Search Console where they informed Google that their preferred domain was a subdomain, and now they want Google to also consider their base domain (without the change of address). How do I get the change of address in Google search console removed?
Technical SEO | | KatherineWatierOng0 -

Event Schema markup for multiple events (same location/address)?
I was wondering if its possible to markup multiple events on the same page for one location/address using the event schema.org markup? I tried doing it on a sample page below: http://www.rama.id.au/event-schema-test/ Google's schema testing tool shows that its all good (except for warning for offers). Just wanted to know if I am doing it correctly or is there a better solution. Any help would be much appreciated. Thank you 🙂
Technical SEO | | Vsood0 -

Should I block Map pages with robots.txt?
Hello, I have a website that was started in 1999. On the website I have map pages for each of the offices listed on my site, for which there are about 120. Each of the 120 maps is in a whole separate html page. There is no content in the page other than the map. I know all of the offices love having the map pages so I don't want to remove the pages. So, my question is would these pages with no real content be hurting the rankings of the other pages on our site? Therefore, should I block the pages with my robots.txt? Would I also have to remove these pages (in webmaster tools?) from Google for blocking by robots.txt to really work? I appreciate your feedback, thanks!
Technical SEO | | imaginex0 -

Does Title Tag location in a page's source code matter?
Currently our meta description is on line 8 for our page - http://www.paintball-online.com/Paintball-Guns-And-Markers-0Y.aspx
Technical SEO | | Istoresinc The title tag, however sits below a bunch of code on line 237
The title tag, however sits below a bunch of code on line 237
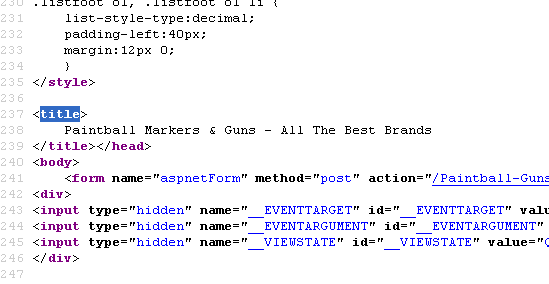 Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0
Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0 -
Block Baidu crawler?
Hello! One of our websites receives a large amount of traffic from the Baidu crawler. We do not have any Chinese content or do any business with China since our market is Uk. Is it a good idea to block the Baidu crawler in the robots.txt or could it have any adverse effects on SEO of our site? What do you suggest?
Technical SEO | | AJPro0 -

Use webmaster tools "change of address" when doing rel=canonical
We are doing a "soft migration" of a website. (Actually it is a merger of two websites). We are doing cross site rel=canonical tags instead of 301's for the first 60-90 days. These have been done on a page by page basis for an entire site. Google states that a "change of address" should be done in webmaster tools for a site migration with 301's. Should this also be done when we are doing this soft move?
Technical SEO | | EugeneF0 -

Is blocking RSS Feeds with robots.txt necessary?
Is it necessary to block an rss feed with robots.txt? It seems they are automatically not indexed (http://googlewebmastercentral.blogspot.com/2007/12/taking-feeds-out-of-our-web-search.html) And, google says here that it's important not to block RSS feeds (http://googlewebmastercentral.blogspot.com/2009/10/using-rssatom-feeds-to-discover-new.html) I'm just checking!
Technical SEO | | nicole.healthline0 -

Multiple Domains, Same IP address, redirecting to preferred domain (301) -site is still indexed under wrong domains
Due to acquisitions over time and the merging of many microsites into one major site, we currently have 20+ TLD's pointing to the same IP address as our "preferred domain:" for our consolidated website http://goo.gl/gH33w. They are all set up as 301 redirects on apache - including both the www and non www versions. When we launched this consolidated website, (April 2010) we accidentally left the settings of our site open to accept any of our domains on the same IP. This was later fixed but unfortunately Google indexed our site under multiple of these URL's (ignoring the redirects) using the same content from our main website but swapping out the domain. We added some additional redirects on apache to redirect these individual pages pages indexed under the wrong domain to the same page under our main domain http://goo.gl/gH33w. This seemed to help resolve the issue and moved hundreds of pages off the index. However, in December of 2010 we made significant changes in our external dns for our ip addresses and now since December, we see pages indexed under these redirecting domains on the rise again. If you do a search query of : site:laboratoryid.com you will see a few hundred examples of pages indexed under the wrong domain. When you click on the link, it does redirect to the same page but under the preferred domain. So the redirect is working and has been confirmed as 301. But for some reason Google continues to crawl our site and index under this incorrect domains. Why is this? Is there a setting we are missing? These domain level and page level redirects should be decreasing the pages being indexed under the wrong domain but it appears it is doing the reverse. All of these old domains currently point to our production IP address where are preferred domain is also pointing. Could this be the issue? None of the pages indexed today are from the old version of these sites. They only seem to be the new content from the new site but not under the preferred domain. Any insight would be much appreciated because we have tried many things without success to get this resolved.
Technical SEO | | sboelter0