Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Exclude status codes in Screaming Frog
-
I have a very large ecommerce site I'm trying to spider using screaming frog. Problem is I keep hanging even though I have turned off the high memory safeguard under configuration.
The site has approximately 190,000 pages according to the results of a Google site: command.
- The site architecture is almost completely flat. Limiting the search by depth is a possiblity, but it will take quite a bit of manual labor as there are literally hundreds of directories one level below the root.
- There are many, many duplicate pages. I've been able to exclude some of them from being crawled using the exclude configuration parameters.
- There are thousands of redirects. I haven't been able to exclude those from the spider b/c they don't have a distinguishing character string in their URLs.
Does anyone know how to exclude files using status codes? I know that would help.
If it helps, the site is kodylighting.com.
Thanks in advance for any guidance you can provide.
-
Thanks for your help. It literally was just the fact that it had to be done before the crawl began and could not be changed during the crawl. Hopefully this is changed because sometimes during a crawl you find things you want to exclude that you may have not known of their existence before hand.
-
Are you sure it's just on Mac,have you tried on PC? Do you have any other rules in include or perhaps a conflicting rule in exclude? Try running a single exclude rule, also on another small site to test.
Also from support if failing on all fronts:
- Mac version, please make sure you have the most up to date version of the OS which will update Java.
- Please uninstall, then reinstall the spider ensuring you are using the latest version and try again.
To be sure - http://www.youtube.com/watch?v=eOQ1DC0CBNs
-
does the exclude function work on mac. i have tried every possible way to exclude folders and have not been successful while running an analysis
-
That's exactly the problem, the redirects are disbursed randomly throughout the site. Although, and the job's still running, it now appears as though there's almost a 1-2-1 correlation between pages and redirects on the site.
I also heard from Dan Sharp via Twitter. He said "You can't, as we'd have to crawl a URL to see the status code
") You can right click and remove after though!"
You can right click and remove after though!"Thanks again Michael. Your thoroughness and follow through is appreciated.
-
Took another look, also looked at documentation/online and don't see any way to exclude URLs from crawl based on response codes. As I see it you would only want to exclude on name or directory as response code is likely to be random throughout a site and impede a thorough crawl.
-
Thank you Michael.
You're right. I was on a 64 bit machine running a 32 bit verson of java. I updated it and the scan has been running for more than 24 hours now without hanging. So thank you.
If anyone else knows of a way to exclude files using status codes I'd still like to learn about it. So far the scan is showing me 20,000 redirected files which I'd just as soon not inventory.
-
I don't think you can filter out on response codes.
However, first I would ensure you are running the right version of Java if you are on a 64bit machine. The 32bit version functions but you cannot increase the memory allocation which is why you could be running into problems. Take a look at http://www.screamingfrog.co.uk/seo-spider/user-guide/general/ under Memory.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Exclude local host traffic from google analytics
I'm getting a lot of local host referral traffic from an unknown source.I want to get rid of this from my google analytics reports. I've tried this filter - but the traffic still appears. Filtername = local host Filtertype= custom Exclude = filter field referral Filter pattern (.?localhost.?) Any ideas ? thanks in advance.
Technical SEO | | ThomasErb0 -

Exclude price in rich snippet markup
Our site has their prices hidden for non logged in users. Its a woocommerce built site and the rich snippet markups are added by woocommerce. I would like to remove the markup for the price becouse : 1, we would like our customers to register for prices. 2 i dont want to get penalties for not showing the same thing to visitors as to "google" .. Any help or thoughts on this one? Thanks / Jonas
Technical SEO | | knubbz0 -

Does Title Tag location in a page's source code matter?
Currently our meta description is on line 8 for our page - http://www.paintball-online.com/Paintball-Guns-And-Markers-0Y.aspx
Technical SEO | | Istoresinc The title tag, however sits below a bunch of code on line 237
The title tag, however sits below a bunch of code on line 237
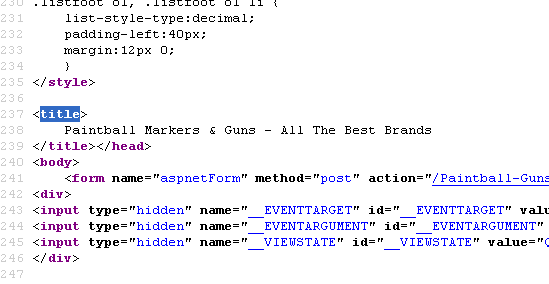 Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0
Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0 -

Diagnosing Canonical Errors Is Screaming frog reliable?
Morning from suny & warm wetherby UK 🙂 On this page http://www.goldsboroughestates.co.uk/how-we-care-for-you/right-to-manage/ screaming frog is citing a canonical error but I'm confused as this piece of code is in place: http://www.goldsboroughestates.co.uk/About/right-to-manage" /> So my question is please - "Does this page http://www.goldsboroughestates.co.uk/how-we-care-for-you/right-to-manage/ have a caninical error or is screaming frog useless? Other examples where screaming frog is picking up canonical errors include:
Technical SEO | | Nightwing
http://www.goldsboroughestates.co.uk/what-our-customers-say/right-to-manage/
http://www.goldsboroughestates.co.uk/buying-a-home/right-to-manage/ Oh forgot to say the preffered version is http://www.goldsboroughestates.co.uk/About/right-to-manage/ Any insights welcvome 🙂0 -

Exclude Child URLs from XML Sitemap Generator (Wordpress)
Hi all, I was recommended the XML Sitemap Generator for Wordpress by the very helpful Keith Bloemendaal and John Pring - however I can't seem to exclude child URLs. There is a section Exclude items and a subsection Exclude posts. I have tried inputting the URLs for the pages I don't want in the sitemap, however that didn't work. So I read that you have to include a list of "IDs" - not sure where on earth to find that info, tried the page name and the post= number from the URL, however neither worked. I hope somebody can point me in the right direction - and apologies, I am a Wordpress novice, and I got no answers from the Wordpress forums so turned right back to SEOmoz! Cheers.
Technical SEO | | markadoi840 -

How much impact does bad html coding really have on SEO?
My client has a site that we are trying to optimise. However the code is really pretty bad. There are 205 errors showing when W3C validating. The >title>, , <keywords> tags are appearing twice. There is truly excessive javascript. And everything has been put in tables.</keywords> How much do you think this is really impacting the opportunity to rank? There has been quite a bit of discussion recently along the lines of is on-page SEO impacting anymore. I just want to be sure before I recommend a whole heap of code changes that could cost her a lot - especially if the impact/return could be miniscule. Should it all be cleaned up? Many thanks
Technical SEO | | Chammy0 -

Is there such thing as a good text/code ratio? Can it effect SERPs?
As it says on the tin; Is there such thing as a good text/code ratio? And can it effect SERPs? I'm currently looking at a 20% ratio whereas some competitors are closer to 40%+. Best regards,
Technical SEO | | ARMofficial
Sam.0 -

Why are apostrophes and other characters still showing as code in my titles?
Hi, I have a WordPress-based site and overall everything is working well. However, I can't seem to figure out how to get apostrophes and other characters to display normally. Now, the problem isn't that they are displaying as code to normal visitors or up in the title bar, they are displaying as code to Google's bots as well as to SEOMOZ. Example: Normal visitor sees: About **** | **** - Metro Vancouver's IT & Web Experts Google and SEOMOZ see: About **** | **** - Metro Vancouver's IT & Web Experts I've played around with different ways of typing the title (not using character codes vs. using character codes) and nothing seems to work. Any help or explanation would be appreciated.
Technical SEO | | Function50